This blog post is part of a series on using large language models for text classification. View the other posts here:
-
LLMs for Text Classification: A Guide to Supervised Learning
-
Unsupervised Text Classification: How to Use LLMs to Categorize Natural Language Data
By Benjamin Nativi, Will Porteous, and Linnea Wolniewicz
The first two posts in our series on text classification using large language models (LLMs) each focused on specific approaches to working with these deep learning tools: supervised learning and unsupervised learning.
Our experiments have shown that both approaches can interact with LLMs successfully to classify text—if certain criteria are met.
But after all the experiments conducted by the Striveworks research and development team, how do they compare? Which method has proven most effective? How can you best use LLMs to classify text? Let’s find out.
Why Use LLMs for Text Classification?
LLMs are such a step change in how machine learning models interact with natural language that they have sparked a revolution in artificial intelligence applications. Millions of people now use LLMs every day to accomplish tasks like building a travel itinerary, writing an email to a colleague, and preparing a cover letter for a job application.
Because they are so adept at certain functions of natural language processing (NLP), we hypothesized that they may be effective at others. Text classification, used widely for spam detection, sentiment analysis, and other purposes, is one of the most fundamental applications of NLP. LLMs were not built for text classification, but their strength in NLP may enable them to perform the task at a high level. If so, they could spawn a new set of applications for this technology. Our experiments set out to put LLMs to the test.
What’s the Difference Between Supervised and Unsupervised Learning?
When looking to use LLMs for text classification, a range of options presents itself. What text should you use for training? Which models? How many data points do you need?
But the most fundamental choice is between supervised learning methods and unsupervised learning methods.
These two approaches make up the two most basic branches of machine learning. To put it simply, supervised learning involves training a model with labeled data. To perform supervised learning, a human needs to take time to annotate a training dataset and feed it into a model. As a result, the model learns the associations between the data points and their labels, which helps it accurately predict labels for similar data it has never seen before.
Unsupervised learning is different. In our case, we were attempting to coax accurate text classifications from a model that had not been trained for this purpose. Instead, it was leveraging the underlying patterns from our prompts to predict outcomes based on their text alone.
Both of these approaches have wide applications, from recommendation engines to face recognition to high-frequency trading. But how do they work with LLMs for text classification?
Supervised Learning for Text Classification With LLMs: A Review
In the first post in this series, we looked at our experiments with supervised learning. Specifically, we discussed how three distinct supervised learning approaches worked for text classification:
- fine-tuning an existing model derived from BERT (a framework with a strong history in NLP)
- fine-tuning an existing model using Low-Rank Adaptation (LoRA)
- applying transfer learning to a classification head, which leveraged a trained model from another use case
Supervised Learning Results
For our experiments, we tested all three methods of text classification against the Text REtrieval Conference (TREC) Question Classification dataset—a common dataset used widely for training, testing, and evaluating the performance of text classification models.
As expected, all three of these methods achieved high F1 scores, showing that they can produce accurate results. Yet, the results were highly dependent on the amount of training data used.
The fine-tuned LoRA model consistently performed best across all training sizes, returning an F1 score of 0.8 or above, regardless of the number of data points it was trained on. However, the pre-LLM DistilRoBERTa model displayed poor performance when less training data was used. It returned F1 scores below 0.7 until it had ingested 512 examples from the TREC training set. The transfer learned classification head split the difference, starting with better results than DistilRoBERTa, even with only 16 training datums, and scaling to an F1 score of greater than 0.8 by the time it had seen 256 data points.
But F1 score isn’t the only metric to consider. While both the LoRA model and the classification head produced strong results, the LoRA model took much longer to train. Because of the design of the model, it took 50 minutes using a single GPU to fine-tune a LoRA model on 512 data points. Conversely, we were able to train the transfer learned classification head on the same data in only 2.56 minutes. This speed and reduced compute give an edge to transfer learned classification heads for text classification—unless you have access to a lot of computing power.
Unsupervised Learning for Text Classification With LLMs: A Review
Unsupervised learning offers an alternative to training LLMs for text classification, one with real advantages if effective. While fine-tuned LLMs can produce accurate results, there are challenges to using them—specifically, the need to work from an annotated dataset. Data annotation demands a lot of effort from humans, who must manually label hundreds or thousands of data points. If unsupervised learning with very little labeled data could produce good results from an LLM through prompt engineering, it would reduce the resources needed to deploy these technologies.
Our experiments in unsupervised learning focused on constructing prompts for LLMs to classify articles from the AG News dataset—a common dataset of news articles used for training and evaluating NLP models.
For these experiments, we crafted a standard instruction to use for all trial runs:
“Classify the news article as world, sports, business, or technology news.”
As part of our prompts, we also provided our test models with the headline for the article to classify, as well as a class field to elicit an appropriate response. For example:
“Article: Striveworks secures patent for innovative data lineage process
Class:”
For each article in the AG News test set, the prompt included the instruction, the article to be classified, and a cue for the model’s answer. We also conducted several experiments that involved k-shot prompting, where we included examples (aka “shots”) as part of the prompt—ranging from batches of four shots to 23 shots. Additional experiments aimed to determine whether or not different sampling strategies would increase performance without increasing computation. We also explored the effects of ensembling, a process that aggregates the results from multiple models or multiple runs using the same model. We tested several LLMs including:
Unsupervised Learning Results
Results from these experiments showed that simple, zero-shot prompts were unable to generate good text classification results from smaller LLMs such as Llama-7b, Llama-2-7b, Alpaca, and GPT4All. Zero-shot prompting did produce a significant F1 score above 0.8 with GPT-3.5, but this model has limitations as a proprietary model from OpenAI.
Incorporating shots into our prompts raised the F1 score when using the smaller, open-source models. Sixteen shots were necessary to initially return an F1 score above 0.8 from these models, and 23 shots were required to maintain that score reliably across runs. The ensembling experiments showed that ensembling raised F1 scores and reduced variations in performance, but they also showed that smaller ensembles with high shot counts outperformed large ensembles with low shot counts.
How To Use LLMs for Text Classification
So, what is the most effective means of classifying text using LLMs? It depends.
Our experiments showed that various methods of working with LLMs for text classification can deliver worthwhile results. As shown in Figure 1, four different unsupervised methods are capable of producing F1 scores that rival the accuracy of the transfer learned classification head.
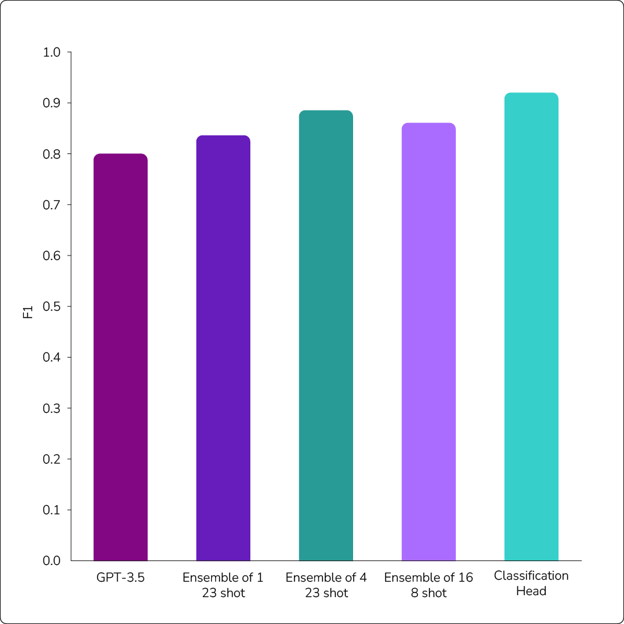
Figure 1: Results of supervised and unsupervised learning experiments in using LLMs for text classification.
Can I just use ChatGPT to classify text?
If model deployment isn’t a concern, users can classify text using GPT-3.5. However, it was the worst-performing model in our tests.
What text classification method should I use if I want better results?
If data teams want stronger results, they need to deploy and maintain an LLM over which they have control, such as Llama. In our experiments, Llama proved more effective at text classification because we were able to directly interact with the machinery of the open-source model—allowing us to examine its logits, which we could not do with the closed, proprietary GPT-3.5.
Do I need to include shots in my prompts to get accurate text classifications?
Yes: Shots improve performance. When working with Llama and other LLMs, our findings show that users can produce accurate text classifications by including a large number of shots in their prompts—as many as possible given the available context size (for Llama, that’s approximately 23 shots per prompt).
Do I need to ensemble several runs to get good results?
Ensembling is very helpful but not at the expense of including shots in the prompt. As shown in Figure 1, ensembles of four with 23 shots consistently outperform ensembles of 16 runs that each included eight shots—suggesting that this is the most effective strategy for working with these LLMs.
Of course, a classification head trained on a full 120,000-point dataset produces the most accurate text classifications. However, this approach requires significant work up front to annotate a dataset. Ensembling four runs of 23-shot prompts generates an F1 score almost as good with only 96 labeled data points.
What text classification method should I use if I have labeled data?
Ultimately, if users have access to labeled data or they are willing to label more data to improve performance, supervised learning methods are the way to go. A fine-tuned LoRA model showed exceptional performance, and a classification head performed almost as well with much less strain on computational resources. However, even users without a lot of labeled data are in luck. K-shot prompting with ensembling—especially ensembles that include as many shots as possible—can also produce quite accurate results.
Even though LLMs are designed for generative purposes rather than text classification tasks, they are a robust new technology for broad NLP projects. They just require a commitment to experimentation—and a lot of shots.
Want to know more about using LLMs? Reach out today to learn how the Striveworks platform can help you build, deploy, and maintain LLMs in both cloud and on-prem environments.
